A Unicode Presentation slide deck is available here
Introduction to Character Set Encoding and Data Collisions

Occasionally you may find a web page that renders a series of nonsense characters in the midst of otherwise sensible text.
The nonsense characters may be question marks inside black diamonds, or inverted question marks, or things that look like à (the A-Tilde) or Š(the A-Ring) followed by some other characters.
Whenever you see this, it's the signature of a character set encoding error.
While there are many ways to botch character set encoding, as a practical matter these errors almost always arise when Extended-ASCII data and UTF-8 data are intermixed.
Extended-ASCII and UTF-8 collisions are becoming more and more common as UTF-8 encoding becomes the preferred form. Older systems that had support for only 8-bit characters are being modernized. In the process, we are uncovering stored data sets with characters that can be represented in both Extended ASCII and UTF-8, but that are represented differently in Extended-ASCII and UTF-8. It is this difference that leads to the collision. The collisions can occur on any one-byte character that resides above decimal code point 127 (binary 0111 1111, hexadecimal code point 7F). Characters that can be troublesome, and are common in existing files, include the Euro and other currency symbols (but not the Dollar), superscripts, fractions and Western European accented characters.
This article will tell some of the history of character encoding and explain some of the ways to deal with older data sets, including MySQL data bases.
A Brief History of ASCII Code
Once upon a time, computer memory and storage was very expensive. And all of the computers in the world (for practical purposes) were in the hands of English-speaking countries. ASCII stands for American Standard Code for Information Interchange. The original 128 ASCII characters were numbered from zero to 127. The first 32 numeric positions and position 127 were control characters. The remaining positions were used to identify Arabic numbers, Latin letters, and some punctuation. The original 7-bit ASCII codes and the 8-bit Extended-ASCII codes are shown in this table:
http://www.ascii-code.com/
Extended ASCII
With an additional bit at the leftmost position of the 7-bit code, we gained an additional 128 characters. The use of these additional characters to represent printable glyphs began in the mid-1980's and varied from one implementation to the next. Some standards attempted to use language-specific information (not encoded into the character set) to represent the mapping of the code point to the glyph. That eventually failed and what emerged was commonly called Latin-1 or ISO-8859-1. ISO-8859-1 provided complete character coverage for many western languages and it was compatible with the 7-bit ASCII codes. Microsoft had a mostly-compatible mapping in the Windows-1252 character set.
While this was an improvement over ASCII, the 8-bit codes were still wanting. For example, ISO-8859-1 is missing the Euro sign at code point 128, but Windows-1252 renders the Euro at code point 128. Windows-1252 has characters that often get converted to unassigned glyphs. And the non-Western languages including Chinese and Korean are unrepresented (and unrepresentable) in only 256 total characters. Clearly we needed a universal character set, but that need had to incorporate the reality that an overwhelming amount of programming and data was based in the ASCII and Extended-ASCII encoding schemes.
Emergence of UTF-8
Many versions of a universal character set emerged.
All of them shared some common features - preservation of the ASCII primitives and multibyte representations for a wide variety of characters.
But there were problems, too. Byte Order Marks at the beginning of documents were required in some implementations.
The programs used these BOMs to understand the encoding.
Like the language-specific ambiguity in Extended ASCII, this was unwieldy - you always had to read documents from the very beginning to understand the encoding.
In 1992, Thompson and Pike brought forth the self-synchronizing coding scheme that became UTF-8. It preserved the one-byte ASCII characters and provided a multibyte extension that allowed characters to be represented by zero, one, two or three additional bytes. The number of additional bytes was given in the high-order bits of the leading byte. The encoding scheme was an instant success and grew rapidly in popularity. In November 2003, RFC 3629 limited UTF-8 to a maximum of four bytes per character in order to match the constraints of the UTF-16 character encoding. In 2008, Google reported that UTF-8 had become the most common encoding for HTML files. Today, some files require UTF-8 encoding, for example, JSON strings. For more information on JSON and UTF-8, look for "Detecting JSON Errors" near the end of this article.
Here is what the encoding scheme looks like
UTF-8 Encoding
bytes bits* representation
1 7 0bbb bbbb
2 11 110b bbbb 10bb bbbb
3 16 1110 bbbb 10bb bbbb 10bb bbbb
4 21 1111 0bbb 10bb bbbb 10bb bbbb 10bb bbbb
*bits used in character representation, aside from the UTF-8 signal bits
Part of the genius of UTF-8 is that ASCII can be considered a 7-bit encoding scheme for a very small subset of Unicode/UCS, and seven-bit ASCII (when prefixed with 0 as the high-order bit) is valid UTF-8. Thus it follows that UTF-8 cannot collide with ASCII. But UTF-8 can and does collide with Extended-ASCII.
The UTF-8 Dead Zone
If you look carefully at the UTF-8 encoding scheme, you will see that any UTF-8 multibyte character begins with a byte with the two leftmost bits set to 11. And the continuation bytes have the two leftmost bits set to 10. Because of this, you would never have a UTF-8 character with a pattern like 10bb bbbb, unless it was one of the continuation bytes of the multibyte characters. So there are no UTF-8 characters with the bit patterns 1000 0000 to 1011 1111 (decimal 128 to 191, hexadecimal 80 to BF). The presence of any single-byte character in this range means that the document cannot be valid UTF-8.
Where the Collisions are Commonplace
Extended-ASCII, with numeric code points between 128 to 255 decimal (80 to FF hexadecimal, 1000 0000 to 1111 1111 binary),
collides with UTF-8 because it has the leftmost bit set to one, and this tells the interpreter that one (at least one) additional byte is required to form the character.
A common collision occurs when data with western-European special or accented characters has been stored in ISO-8859-1. In the one-byte encoding, the Æ (AE Ligature) character is represented by decimal code point 198, which is hex C6, binary 1100 0110. Since the two high-order bits are set, the UTF-8 interpretation of the AE Ligature would imply a two byte character, and the interpreter would look at the next byte to render the AE Ligature character (the UTF-8 AE Ligature is hexadecimal C386). Similar collisions occur with accents, umlauts, tildes, rings and some currency symbols.
How to Detect Potential Collisions in PHP
PHP has a bit of a conundrum over one-byte versus multibyte characters. To quote the PHP manual about the string data type, "A string is series of characters, where a character is the same as a byte. This means that PHP only supports a 256-character set, and hence does not offer native Unicode support. See details of the string type."
Thud! In UTF-8 a character is not the same as a byte!
Given that PHP does not dictate a specific encoding for strings, one might wonder how string literals are encoded.
For instance, is the string á equivalent to one-byte hexadecimal E1 (ISO-8859-1) or two-byte hexadecimal C3A1 (UTF-8)?
Unfortunately the answer is "it depends." The answer will be whatever character encoding was in use at the time the string literal was created.
As you may have guessed, your settings of your text editor or IDE are in play here.
Are your PHP source code files written with UTF-8 in mind?
To make matters worse, PHP's mb_detect_encoding()
function will be able to tell that this is not an ASCII character, but will be unable to distinguish between ISO-8859-1 and UTF-8.
At this writing, PHP's most frequently used character encoding is Extended ASCII rendered in ISO-8859-1. That is about to change.
PHP's Changing Posture at Release 5.4+
PHP htmlentities() and htmlspecialchars() are changing their default functionality. Since these functions are widely used as security measures to prepare browser output, you may want to read the important note on the man pages, "Like htmlspecialchars(), htmlentities() takes an optional third argument encoding which defines encoding used in conversion. If omitted, the default value for this argument is ISO-8859-1 in versions of PHP prior to 5.4.0, and UTF-8 from PHP 5.4.0 onwards [ed.note: changed again at PHP 5.6]. Although this argument is technically optional, you are highly encouraged to specify the correct value for your code."
Some Test Data, Our Expectations, and Symptoms of Collision
Test data is the programmer's most important tool, so we need some samples to work with. These strings contain ISO-8859-1 characters that collide with UTF-8. They will help us when we want to create the SSCCE test cases.
// TEST CASES
$arr
= array
( 'Françoise'
, 'Å-Ring'
, 'ßeta or Beta?'
, 'Öh löök, umlauts!'
, 'ENCYCLOPÆDIA'
, 'ça va! mon élève mi niña?'
, 'A stealthy ƒart'
, 'Ðe lónlí blú bojs'
)
;
Here is what we would expect to see.
 What do these ISO-8859-1 characters look like when they are rendered in the browser, and the browser has been told it's getting UTF-8 characters?
What do these ISO-8859-1 characters look like when they are rendered in the browser, and the browser has been told it's getting UTF-8 characters?
 What if we write these strings in UTF-8, but the browser has been told to render Extended ASCII (ISO-8859-1 or Windows-1252)?
What if we write these strings in UTF-8, but the browser has been told to render Extended ASCII (ISO-8859-1 or Windows-1252)?

What to Do to Convert Extended ASCII to UTF-8
PHP provides the utf8_encode() function. It recognizes the Extended ASCII character set to be ISO-8859-1 and converts the single-byte characters above code point 127 into UTF-8 multibyte characters. The conversion is a "mung" that cannot be done more than once (see the code snippet in "Pitfalls" below). If any characters are converted, the strlen() of the output string will be greater than the strlen() of the input string.
What to Do to Convert UTF-8 to ISO-8859-1
PHP provides the utf8_decode() function. It tries to convert UTF-8 characters into one-byte ISO-8859-1 characters. Obviously this has its shortcomings, since there are many more UTF-8 characters than ISO-8859-1 characters. If the function cannot create an accurate mapping, the resulting text may be garbled or characters may go missing. And beware of the Euro, which is missing in ISO-8859-1. A good strategy might be to use the character entity €.
Potential Pitfalls in PHP
The function utf8_encode() assumes that its input is a string in ISO-8859-1 encoding. If a script accidentally feeds this function a UTF-8 string, an "interesting" result will appear. Try this little script to see what happens.
<?php // RAY_EE_Character_Collisions_recode.php
error_reporting(E_ALL);
// SET THE INTERNAL ENCODING
$charset = 'iso-8859-1';
mb_internal_encoding($charset);
mb_http_output($charset);
// MAKE A TEST STRING
$str = 'Öh löök, umlauts!';
// "ACCIDENTALLY" UTF8_ENCODE() IT MORE THAN ONCE
$new = $str;
$new = utf8_encode($new);
$new = utf8_encode($new);
$new = utf8_encode($new);
// GET THE STRING LENGTHS
$str_strlen = strlen($str);
$new_strlen = strlen($new);
// SHOW WHAT HAPPENDED
$html5 = <<<ENDHTML5
<!DOCTYPE html>
<html dir="ltr" lang="en-US">
<head>
<meta charset="$charset" />
<title>CHARACTER ENCODING STRING LENGTHS</title>
</head>
<body>
<pre>
ORIGINAL STRING POS 1...5...10...15...20...25...
ORIGINAL STRING IS: $str
ENCODED STRING IS: $new
THE ISO STRLEN() IS: $str_strlen
THE UTF STRLEN() IS: $new_strlen
ENDHTML5;
echo $html5;
The function utf8_decode() assumes that its input is a string with UTF-8 encoding and the function utf8_encode() assumes an ISO-8859-1 encoding. This is a reasonable assumption, given the history of PHP, but this means that Windows-1252 strings may produce incorrect output if they are passed into utf8_encode(). A better solution may be found in iconv(), but even this has its flaws and risks.
Since PHP string functions assume that one byte == one character, the PHP substr() function may cause a failure by choosing a byte-boundary in the middle of a multibyte character. A better solution for UTF-8 text would be mb_substr(), which does not make assumptions about the byte:character relationship but instead obeys the setting of mb_internal_encoding().
PHP cannot convert characters outside of the ISO-8859-1 character set, even if your browser can display them correctly.
Case in point: The Euro and the Florin are lost when PHP performs the conversion.
To see the symptom, install a script with those characters and look at it with charset=iso-8859-1 then look again with charset=utf-8.
BOM is Decidedly Not Da Bomb
Byte Order Marks are not necessary or appropriate in UTF-8 documents. Don't use them. PHP has a way to remove the BOM from a document. Beware that some text editors, including Notepad, may actually create and insert BOMs into your UTF-8 documents. This is unfortunate, since it encourages a dependency on a legacy artifact that is no longer needed nor appropriate with UTF-8. The best you can do is be aware of BOMs, avoid them when possible and remove them when you encounter them. A signature of the BOM is something like this at the start of your document: 
Character Sets in MySQL
You really want consistency across your server files, your PHP scripts, your browser meta-charset and your data base. To that end, MySQL has settable character sets. In a perfect world, the proper character set will be set at the server level. See MySQL Character Set Configuration for more on this. In addition, each MySQL API offers a method to set the character set at run time.
How not to do it: mysql_query('SET NAMES utf8'); This should be avoided if possible for the reason that it does not play well with the escape functions and PDO::quote(). Details here.
Instead, choose one of the recommended ways that are documented on the appropriate man pages.
// MySQL (DEPRECATED)
// MAN PAGE https://php.net/manual/en/function.mysql-set-charset.php
mysql_set_charset('utf8mb4');
// MYSQLi
// MAN PAGE https://php.net/manual/en/mysqli.set-charset.php
$mysqli = new mysqli("localhost", "my_user", "my_password", "test");
$mysqli->set_charset("utf8mb4");
// PDO (RELEASE-DEPENDENT)
// MAN PAGE https://php.net/manual/en/ref.pdo-mysql.connection.php
$pdo = new PDO("mysql:host=localhost;dbname=world;charset=utf8mb4", 'my_user', 'my_pass');
If you need to convert an existing MySQL table to UTF-8, you might want to use ALTER TABLE to change the width of the columns so that the multi-byte characters will fit into the table. It is advisable to back up the table first. The change made by CONVERT TO CHARACTER SET does not change the contents of the table, nor the data that is returned by the query.
https://php.net/manual/en/mysqlinfo.concepts.charset.php#109884
https://dev.mysql.com/doc/refman/5.1/en/alter-table.html
This script demonstrates how Extended-ASCII characters can be stored in a MySQL table and subsequently retrieved in UTF-8 format. Some discussion is in order. The URL parameter charset= is used to set the browser display character set. This has no effect on the internal data, but it affects the way you see the output. If you set this to ISO-8859-1 you will see correct output from the Latin1 data, but the UTF-8 data may be garbled. If you set this to UTF-8, you will see missing characters in the Latin1 data, but the UTF-8 data will be correct.
MySQL has a gotcha lurking in the way it handles UTF-8 information. The encoding you want to use is not simply called utf8. MySQL uses a three-byte encoding scheme if you tell it to use utf8. What you really want instead is utf8mb4, giving you full four-byte capabilities.
Annotation of the code follows.
Line 9: Choose the display character set and use the <meta> tag to tell the browser
Line 18: Connect and select the data base
Line 40: This is probably the default character set
Line 44-104: Create and load a test data set
Line 107-134: Retrieve the data set using the Latin1 character set and PHP single-byte mode
Line 137: Change MySQL and PHP to UTF-8 mode
Line 142-169: Retrieve the data set using the UTF-8 character set and PHP multi-byte mode
Line 173-206: A utility function that will show us the hexadecimal byte values.
Note that to retrieve UTF-8 data you must run the query after set_charset(). A data_seek() will simply retrieve the Latin1 strings again.
<?php // demo/mysqli_latin1_to_utf8.php
error_reporting(E_ALL);
// EXTENDED-ASCII CHARACTERS COLLIDE WITH UTF-8 ENCODINGS AND CANNOT BE RENDERED CORRECTLY
// DEMONSTRATE HOW TO CONVERT A DATA BASE TABLE TO UTF-8
// CHOOSE A BROWSER-DISPLAY CHARSET VALUE FROM THE URL ARGUMENT utf-8, windows-1252, iso-8859-1, iso-8859-15, etc.
$charset = !empty($_GET['charset']) ? $_GET['charset'] : 'ascii';
echo <<<EOD
<meta charset="$charset" />
<pre>
<h3>VIEWING THE DATA WITH CHARSET = $charset</h3>
EOD;
// DATABASE CONNECTION AND SELECTION VARIABLES - GET THESE FROM YOUR HOSTING COMPANY
$db_host = "localhost"; // PROBABLY THIS IS OK
$db_name = "??";
$db_user = "??";
$db_word = "??";
// OPEN A CONNECTION TO THE DATA BASE SERVER AND SELECT THE DB
$mysqli = new mysqli($db_host, $db_user, $db_word, $db_name);
// DID THE CONNECT/SELECT WORK OR FAIL?
if ($mysqli->connect_errno)
{
$err
= "CONNECT FAIL: "
. $mysqli->connect_errno
. ' '
. $mysqli->connect_error
;
trigger_error($err, E_USER_ERROR);
}
// THIS IS PROBABLY THE DEFAULT CHARACTER SET
$mysqli->set_charset('latin1');
// CREATE THE TEST DATA IN EXTENDED ASCII
$iso
= array
( '1' => 'Öh löök, umlauts in the Encyclopædia!'
, '2' => 'At Ðe lónlí blú bojs concert, Françoise ƒlew a paper airplane'
, '3' => 'For €3 (or £2) you can order ½ martini with ± 1 olive: Ý'
)
;
// CREATING A TABLE FOR OUR TEST DATA
$sql
=
"
CREATE TEMPORARY TABLE iso_table
( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, fname VARCHAR(128) NOT NULL DEFAULT ''
)
"
;
if (!$res = $mysqli->query($sql))
{
$err
= 'QUERY FAILURE:'
. ' ERRNO: '
. $mysqli->errno
. ' ERROR: '
. $mysqli->error
. ' QUERY: '
. $sql
;
trigger_error($err, E_USER_ERROR);
}
// LOADING OUR EXTENDED ASCII DATA INTO THE TABLE
foreach ($iso as $fname)
{
// ESCAPE THE DATA FOR SAFE USE IN A QUERY
$safe_fn = $mysqli->real_escape_string($fname);
// CONSTRUCT THE QUERY USING THE ESCAPED VARIABLES
$sql = "INSERT INTO iso_table ( fname ) VALUES ( '$safe_fn' )";
if (!$res = $mysqli->query($sql))
{
$err
= 'QUERY FAILURE:'
. ' ERRNO: '
. $mysqli->errno
. ' ERROR: '
. $mysqli->error
. ' QUERY: '
. $sql
;
trigger_error($err, E_USER_ERROR);
}
// GET THE AUTO_INCREMENT ID OF THE RECORD JUST INSERTED
$id = $mysqli->insert_id;
echo "MySQLI INSERTED ROW $mysqli->insert_id CONTAINING <b>$safe_fn</b>" . PHP_EOL;
}
echo PHP_EOL;
// CONSTRUCT A SELECT QUERY
$sql = "SELECT id, fname FROM iso_table ORDER BY id";
if (!$res = $mysqli->query($sql))
{
$err
= 'QUERY FAILURE:'
. ' ERRNO: '
. $mysqli->errno
. ' ERROR: '
. $mysqli->error
. ' QUERY: '
. $sql
;
trigger_error($err, E_USER_ERROR);
}
// ITERATE OVER THE RESULTS SET AS AN OBJECT TO SHOW WHAT WE FOUND
echo PHP_EOL . 'VIEWING MySQLi_Result::Fetch_Object() WITH LATIN1: ';
echo PHP_EOL;
while ($row = $res->fetch_object())
{
$bytes = strlen($row->fname);
$chars = mb_strlen($row->fname);
echo PHP_EOL . "ID=$row->id $bytes BYTES, $chars CHARACTERS";
echo hexdump($row->fname);
}
echo PHP_EOL;
// SWITCH OVER TO UTF-8
$mysqli->set_charset('utf8mb4');
mb_internal_encoding('utf-8');
// CONSTRUCT A QUERY TO RETRIEVE THE DATA FROM THE TABLE
$sql = "SELECT id, fname FROM iso_table ORDER BY id";
if (!$res = $mysqli->query($sql))
{
$err
= 'QUERY FAILURE:'
. ' ERRNO: '
. $mysqli->errno
. ' ERROR: '
. $mysqli->error
. ' QUERY: '
. $sql
;
trigger_error($err, E_USER_ERROR);
}
// ITERATE OVER THE RESULTS SET AS AN OBJECT TO SHOW WHAT WE FOUND
echo PHP_EOL . 'VIEWING MySQLi_Result::Fetch_Object() WITH UTF-8: ';
echo PHP_EOL;
while ($row = $res->fetch_object())
{
$bytes = strlen($row->fname);
$chars = mb_strlen($row->fname);
echo PHP_EOL . "ID=$row->id $bytes BYTES, $chars CHARACTERS";
echo hexdump($row->fname);
}
echo PHP_EOL;
// UTILITY FUNCTION TO SHOW US THE HEX BYTE VALUES
function hexdump($str, $br=PHP_EOL)
{
if (empty($str)) return FALSE;
// GET THE HEX BYTE VALUES IN A STRING
$hex = str_split(implode(NULL, unpack('H*', $str)));
// ALLOCATE BYTES INTO HI AND LO NIBBLES
$hi = NULL;
$lo = NULL;
$mod = 0;
foreach ($hex as $nib)
{
$mod++;
$mod = $mod % 2;
if ($mod)
{
$hi .= $nib;
}
else
{
$lo .= $nib;
}
}
// SHOW THE SCALE, THE STRING AND THE HEX
$num = substr('1...5...10...15...20...25...30...35...40...45...50...55...60...65...70...75...80...85...90...95..100..105..110..115..120..125..130', 0, strlen($str));
echo $br . $num;
echo $br . $str;
echo $br . $hi;
echo $br . $lo;
echo $br;
}
Using UTF-8 with PDO
You can store and retrieve UTF-8 data in a MySQL data base through PDO if you use the right settings for PHP and PDO. I found that this worked out well.
Line 30-33: Set the PHP encoding
Line 38: Set the Character Set in the DSN
Line 50: Set the MySQL "names"
Line 73: Set the table character set
<?php // demo/pdo_latin1_to_utf8.php
error_reporting(E_ALL);
echo '<pre>';
// EXTENDED-ASCII CHARACTERS COLLIDE WITH UTF-8 ENCODINGS AND CANNOT BE RENDERED CORRECTLY
// DEMONSTRATE HOW TO USE PDO WITH A DATA BASE TABLE IN BOTH EXTENDED-ASCII AND UTF-8
// CHOOSE A BROWSER-DISPLAY CHARSET VALUE FROM THE URL ARGUMENT utf-8, windows-1252, iso-8859-1, iso-8859-15, etc.
$charset = !empty($_GET['charset']) ? $_GET['charset'] : 'utf-8';
$self = $_SERVER['PHP_SELF'];
echo <<<EOD
<meta charset="$charset" />
VIEWING THE DATA WITH BROWSER CHARSET = $charset
<a href="$self?charset=iso-8859-1">ISO-8859-1</a>
<a href="$self?charset=utf-8">UTF-8</a>
EOD;
// DATABASE CONNECTION AND SELECTION VARIABLES - GET THESE FROM YOUR HOSTING COMPANY
$db_host = "localhost"; // PROBABLY THIS IS OK
$db_name = "??";
$db_user = "??";
$db_word = "??";
// SWITCH PHP ENCODING TO UTF-8
$mbie = "utf-8";
mb_internal_encoding($mbie);
mb_http_output($mbie);
echo PHP_EOL . "MULTIBYTE ENCODING($mbie)";
echo PHP_EOL;
// OPEN A NEW CONNECTION TO THE DATA BASE SERVER AND SELECT THE DB
$dsn = "mysql:host=$db_host;dbname=$db_name;charset=utf8mb4";
try
{
$pdo = new PDO($dsn, $db_user, $db_word);
}
catch(PDOException $e)
{
var_dump($e);
die(' NO PDO Connection');
}
// SET PDO TO USE UTF-8
$pdo->setAttribute( PDO::MYSQL_ATTR_INIT_COMMAND, 'SET NAMES utf8mb4');
// SET PDO TO TELL US ABOUT WARNINGS OR TO THROW EXCEPTIONS
$pdo->setAttribute( PDO::ATTR_ERRMODE, PDO::ERRMODE_WARNING );
$pdo->setAttribute( PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION );
// CREATE THE TEST DATA IN UTF-8
$iso
= array
( '1' => 'Öh löök, umlauts in the Encyclopædia!'
, '2' => 'At Ðe lónlí blú bojs concert, Françoise ƒlew a paper airplane'
, '3' => 'For €3 (or £2) you can order ½ martini with ± 1 olive: Ý'
)
;
// CREATING A TABLE FOR OUR TEST DATA - NOTE THE CHARACTER SET
$sql
=
"
CREATE TEMPORARY TABLE iso_table
( id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, fname VARCHAR(128) NOT NULL DEFAULT ''
) CHARACTER SET=utf8mb4
"
;
// RUN QUERY TO CREATE THE TABLE
try
{
$pdos = $pdo->query($sql);
}
catch(PDOException $e)
{
var_dump($e);
}
// PREPARE THE QUERY TO LOAD THE DATA ("PREPARE" ONLY NEEDED ONCE)
$sql
=
"INSERT INTO iso_table
( fname ) VALUES
( :fname )
"
;
try
{
$pdos = $pdo->prepare($sql);
}
catch(PDOException $e)
{
var_dump($e);
}
// LOADING OUR DATA INTO THE TABLE
foreach ($iso as $fname)
{
$fname = utf8_encode($fname);
// USE THE ARRAY OF KEYWORD => VALUE TO ATTACH fname STRING
try
{
// RUN THE QUERY TO INSERT THE ROW
$pdos->execute( array('fname' => $fname) );
}
catch(PDOException $e)
{
var_dump($e);
die();
}
// GET THE AUTO_INCREMENT ID OF THE RECORD JUST INSERTED
$id = $pdo->lastInsertId();
echo "PDO INSERTED A ROW CONTAINING <b>" . $fname . "</b> WITH AUTO_INCREMENT ID = $id" . PHP_EOL;
}
// CONSTRUCT AND RUN A SELECT QUERY
$sql = "SELECT fname FROM iso_table ORDER BY id";
try
{
$pdos = $pdo->query($sql);
}
catch(PDOException $e)
{
var_dump($e);
}
// ITERATE OVER THE RESULTS SET TO SHOW WHAT WE FOUND
echo "USING PDOStatement::FetchAll(PDO::FETCH_OBJ) WITH $mbie: ";
echo PHP_EOL;
while ($rows = $pdos->fetchAll(PDO::FETCH_OBJ))
{
// ROW BY ROW PROCESSING IS DONE HERE
foreach ($rows as $obj)
{
$chars = mb_strlen($obj->fname);
$bytes = strlen($obj->fname);
echo PHP_EOL . "$chars $mbie CHARACTERS; $bytes BYTES: ";
echo PHP_EOL . '1...5...10...15...20...25...30...35...40...45...50...55...60...' . PHP_EOL;
print_r($obj->fname);
echo PHP_EOL;
}
}
Some Code to Experiment With
You might want to install this script on your server and run it. You can adjust the character settings to see the different outcomes (and symptoms of success or failure). Just set the desired character set in the URL like this:
http://iconoun.com/demo/entitize_western_letters.php?charset=windows-1252
<?php // demo/entitize_western_letters.php
error_reporting(E_ALL);
// SOME ASCII CHARACTERS COLLIDE WITH UTF-8 ENCODINGS AND CANNOT BE RENDERED CORRECTLY
// DEMONSTRATE HOW TO TRANSLATE SOME WESTERN CHARACTERS INTO ENGLISH-PRINTABLE, UTF-8 OR ENTITIES
// SEE http://www.joelonsoftware.com/articles/Unicode.html
// CHOOSE A CHARSET VALUE FROM THE URL ARGUMENT utf-8, windows-1252, iso-8859-1, iso-8859-15, etc.
$charset = isset($_GET['charset']) ? $_GET['charset'] : 'ascii';
// START WITH HTML5 DOCTYPE AND WHATEVER CHARSET
$html5 = <<<ENDHTML5
<!DOCTYPE html>
<html dir="ltr" lang="en-US">
<head>
<meta charset="$charset" />
<title>CHARACTER SET $charset</title>
</head>
<body>
<pre>
YOU MIGHT WANT TO USE "VIEW SOURCE" TO LOOK AT THESE
THE ORIGINAL CHARACTER SET IS <b>$charset</b>
ENDHTML5;
echo $html5;
// TEST CASES
$arr
= array
( 'Françoise'
, 'Å-Ring'
, 'ßeta or Beta?'
, 'Öh löök, umlauts!'
, 'ENCYCLOPÆDIA'
, 'ça va! mon élève mi niña?'
, 'A stealthy ƒart'
, 'Ðe lónlí blú bojs'
)
;
// DISPLAY EACH TEST CASE USING ENTITIZED CHARACTERS
echo PHP_EOL . 'USING NUMERICALLY ENTITIZED CHARACTERS';
foreach ($arr as $str)
{
echo PHP_EOL
. $str
. ' = '
. '<strong>'
. mungstring($str, 'ENT')
. '</strong>'
;
}
echo PHP_EOL;
// DISPLAY EACH TEST CASE USING TEXT TRANSLATIONS
echo PHP_EOL . 'USING TEXT TRANSLATIONS';
foreach ($arr as $str)
{
echo PHP_EOL
. $str
. ' = '
. '<strong>'
. mungstring($str, 'TXT')
. '</strong>'
;
}
echo PHP_EOL;
// DISPLAY EACH TEST CASE USING UTF-8 TRANSLATIONS
echo PHP_EOL . 'USING UTF-8 CONVERSIONS';
foreach ($arr as $str)
{
echo PHP_EOL
. $str
. ' = '
. '<strong>'
. mungstring($str, 'UTF')
. '</strong>'
;
}
echo PHP_EOL;
// EXAMPLE SHOWING HOW TO TURN A PORTUGESE NAME INTO PART OF A URL STRING
$str = 'Armação de Pêra';
$new = mungString($str);
$new = strtolower($new);
$new = str_replace(' ', '-', $new);
// SHOW THE URL STRING
echo PHP_EOL
. '<strong>'
. '<a target="blank" href="http://lmgtfy.com?q='
. $new
. '">'
. mungString($str, 'Ent')
. '</a>'
. '</strong>'
;
// EXAMPLE SHOWING HOW TO TURN A STRING INTO A NUMERICALLY ENTITIZED STRING
echo PHP_EOL;
$str = 'Armação de Pêra';
$new = mungString($str, 'ENTITIES');
echo PHP_EOL
. $new
. ' = '
. '<strong>'
. htmlentities($new)
. '</strong>'
;
// EXAMPLE SHOWING ALL THE ORIGINAL LETTERS
echo PHP_EOL;
print_r( mungstring(NULL, NULL) );
// A FUNCTION TO RETURN THE WESTERNIZED/ENTITIZED STRING
function mungString($str, $return='TEXT')
{
// OUR REPLACEMENT ARRAY OF ENTITIES
static
$entity
= array();
// OUR REPLACEMENT ARRAY OF UTF-8 CHARACERS
static
$utf8
= array();
// OUR REPLACEMENT ARRAY OF CHARACTERS (YOU MAY WANT SOME CHANGES HERE)
static
$normal
= array
( 'ƒ' => 'f' // http://en.wikipedia.org/wiki/%C6%91 florin
, 'Š' => 'S' // http://en.wikipedia.org/wiki/%C5%A0 S-caron (voiceless postalveolar fricative)
, 'š' => 's' // http://en.wikipedia.org/wiki/%C5%A0 s-caron
, 'Ð' => 'Dh' // http://en.wikipedia.org/wiki/Eth (voiced dental fricative)
, 'Ž' => 'Z' // http://en.wikipedia.org/wiki/%C5%BD Z-caron (voiced postalveolar fricative)
, 'ž' => 'z' // http://en.wikipedia.org/wiki/%C5%BD z-caron
, 'À' => 'A'
, 'Á' => 'A'
, 'Â' => 'A'
, 'Ã' => 'A'
, 'Ä' => 'A'
, 'Å' => 'A'
, 'Æ' => 'E'
, 'Ç' => 'C'
, 'È' => 'E'
, 'É' => 'E'
, 'Ê' => 'E'
, 'Ë' => 'E'
, 'Ì' => 'I'
, 'Í' => 'I'
, 'Î' => 'I'
, 'Ï' => 'I'
, 'Ñ' => 'N'
, 'Ò' => 'O'
, 'Ó' => 'O'
, 'Ô' => 'O'
, 'Õ' => 'O'
, 'Ö' => 'O'
, 'Ø' => 'O'
, 'Ù' => 'U'
, 'Ú' => 'U'
, 'Û' => 'U'
, 'Ü' => 'U'
, 'Ý' => 'Y'
, 'Þ' => 'Th' // http://en.wikipedia.org/wiki/Thorn_%28letter%29 (Capital Thorn is smaller)
, 'ß' => 'Ss'
, 'à' => 'a'
, 'á' => 'a'
, 'â' => 'a'
, 'ã' => 'a'
, 'ä' => 'a'
, 'å' => 'a'
, 'æ' => 'e'
, 'ç' => 'c'
, 'è' => 'e'
, 'é' => 'e'
, 'ê' => 'e'
, 'ë' => 'e'
, 'ì' => 'i'
, 'í' => 'i'
, 'î' => 'i'
, 'ï' => 'i'
, 'ð' => 'dh' // http://en.wikipedia.org/wiki/Eth
, 'ñ' => 'n'
, 'ò' => 'o'
, 'ó' => 'o'
, 'ô' => 'o'
, 'õ' => 'o'
, 'ö' => 'o'
, 'ø' => 'o'
, 'ù' => 'u'
, 'ú' => 'u'
, 'û' => 'u'
, 'ý' => 'y'
, 'ý' => 'y'
, 'þ' => 'th' // http://en.wikipedia.org/wiki/Thorn_%28letter%29
, 'ÿ' => 'y'
)
;
// THE EXPECTED RETURN
$r = strtoupper(substr($return,0,1));
// RETURN THE "TRANSLATED" TEXT
if ($r == 'T') return strtr($str, $normal);
// RETURN THE "ENTITIZED" TEXT
if ($r == 'E')
{
if (empty($entity))
{
foreach ($normal as $key => $nothing)
{
$entity[$key] = '&#' . ord($key) . ';';
}
}
return strtr($str, $entity);
}
// RETURN THE UTF-8 TEXT
if ($r == 'U')
{
if (empty($utf8))
{
foreach ($normal as $key => $nothing)
{
$utf8[$key] = utf8_encode($key);
}
}
return strtr($str, $utf8);
}
// MIGHT BE USEFUL TO GET THE LIST OF ORIGINAL LETTERS
return array_keys($normal);
}
UTF-8 in Microsoft Applications
Most Microsoft "Office Productivity" applications make the assumption that your data is in ANSI format, generally rendering the data in CP-1252 or a similar character set, without regard to the fact that the data may be UTF-8 encoded. As a result, you will see the garbled data strings that are emblematic of UTF-8 data rendered in ISO-8859-1 encoding. This comes into play if your scripts write CSV files that need to be opened in Excel. Although the Excel software is almost universally associated with the .csv file suffix, it appears that Excel does not yet recognize UTF-8 data, unless you tell Excel that the data is UTF-8. Since UTF-8 is self-evident, this ability should be built into Excel some day. And the good news is that it appears that the Microsoft applications preserve the data values, even though they garble the screen rendering (I have only tested this Excel .csv and .xlsx files). Until then you can use this workaround from Princeton University Institute of Advanced Studies.
http://www.itg.ias.edu/content/how-import-csv-file-uses-utf-8-character-encoding-0
Copy-and-Paste From Microsoft Word®
If you have an HTML form with a <textarea> input control, eventually someone is going to create a document in Word, copy some or all of the document, and paste it into your <textarea>.
If your web site is using the ISO-8859-1 character set, the special quotes and other quirky characters that Word creates will go through unalloyed.
But if your site is using UTF-8, there will be a character collision and the display of the <textarea> data will look awful.
Fortunately there is an easy way around this issue, via a built-in PHP function.
Get_HTML_Translation_Table() can be used to turn the special Word characters into named HTML entities.
These entities will be displayed correctly in any browser. Here is a sample script that shows how it works.
You can install this on your server and run it to see the translation in action. It comes with a gentle warning, however.
When your script turns special characters into entities, single bytes are expanded into something that looks like » and the data string gets longer.
This means that you incur a risk of data truncation if your script translates the data before storing it in your data base.
Check your column widths carefully to avoid data loss.
<?php // RAY_fixWord.php
error_reporting(E_ALL);
// REF http://www.w3.org/TR/WD-html40-970708/sgml/entities.html
// REF http://en.wikipedia.org/wiki/List_of_XML_and_HTML_character_entity_references
// REF http://php.net/manual/en/function.strtr.php#23384
// REF http://php.net/manual/en/function.get-html-translation-table.php (SEE ENCODING)
function fixWord($str, $enc='UTF-8')
{
$ent = get_html_translation_table(HTML_ENTITIES, ENT_QUOTES, $enc);
return strtr($str, $ent);
}
// SET THE CHARACTER SET ENCODING FOR THE WEB PAGE AND FOR THE TRANSLATION TABLE
$charset = !empty($_GET['charset']) ? $_GET['charset'] : 'utf-8';
// DEFINE AND CLEAR SOME VARIABLES
$s = $o = $e = NULL;
// IF THERE IS SOME TEXT
if (!empty($_POST['t']))
{
$o = $_POST['t'];
$s = fixWord($_POST['t'], $charset);
$e = htmlentities($s);
}
// CREATE OUR WEB PAGE IN HTML5 FORMAT
$htm = <<<HTML5
<!DOCTYPE html>
<html dir="ltr" lang="en-US">
<head>
<meta charset="$charset" />
<meta name="robots" content="noindex, nofollow" />
<title>Entitize WORD® for Windows Cut/Paste</title>
</head>
<body>
<p>
ORIGINAL: $o
<br/>TRANSLATED: $s
<br/>ENTITIES: $e
</p>
<form method="post">
Copy and paste from a Microsoft Word® document:
<br/>
<textarea name="t">$o</textarea>
<br/>
<input type="submit" value="Entitize Microsoft Word® Characters" />
</form>
</body>
</html>
HTML5;
// RENDER THE WEB PAGE
echo $htm;
Errors Introduced by Text Editors
Consider the following code snippet, created using a Mac program called TextWrangler.
At first glance it looks OK, but try installing the HTML and rendering the web page.
It fails, and depending on your character set encoding, you may see something like this:
The requested URL /genealogy/Letters/“1890-Dec-7.jpg" was not found on this server
The reason for this failure is the leading quotation mark before 1890-Dec-j.jpg. It's not the quotation mark at decimal code point 34! It looks a lot like a quotation mark, enough so that it's visually confusing. But it's actually a multibyte symbol, akin to the left-angle and right-angle quotes that Microsoft Word often creates. Browsers look for a quotation mark to encapsulate the attribute values in HTML tags, but if they find no quote, they try to degrade "gracefully" by acting as if the quote had been included. (It would be so much easier to get this right if the browsers would enforce strict standards and issue error messages, but that's a conversation for another day). As a result, the HTML document cannot be rendered correctly and the links are broken. You may want to check your text editor to see that it renders quotation marks in a way that is compatible with the meaning of the HTML tags.
<tr>
<td>7 Dec 1890</td>
<td><a href=“1890-Dec-7.jpg" target=“_blank”>Original</a></td>
<td>Ericksen</td>
<td> </td>
</tr>
Detecting JSON Errors
At this writing (Early 2014) JSON has eclipsed XML as the transport mechanism of choice. This makes sense; JSON is substantially more compact than XML because the end tags are omitted. And JSON can readily be consumed in most programming languages, including JavaScript on the client machine and PHP on the server.
One of the nagging problems with malformed JSON in PHP is the PHP error reporting scheme. When the JSON-related PHP scripts fail you can find a message in the function json_last_error() and you can retrieve the message text with json_last_error_message(). But the error messages are notoriously terse and do not tell you anything beyond the type of error.
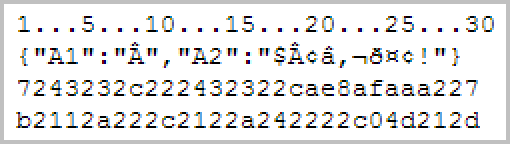
At some point you will find yourself dealing with a very long JSON string (several thousand bytes is commonplace) that contains a malformed UTF-8 character. When this happens PHP json_decode() returns NULL instead of an object and you will need to find the malformed character. That needle-in-the-haystack problem is a troubling issue, because finding a single malformed character in thousands of characters is not easy. To try to illustrate the problem, consider these images (enlarged to make the type easier to read). The first image shows the malformed JSON string rendered with ANSI encoding. Notice the A-circumflex? That is a malformed UTF-8 character. The correctly formed JSON UTF-8 multibyte characters are garbled.
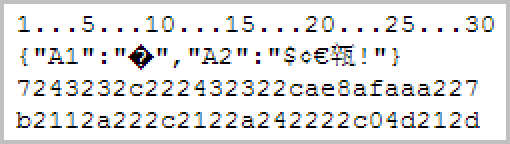
 The second image shows the malformed JSON string rendered with UTF-8 encoding. In this image we see a marker in place of the malformed character, and the UTF8 multibyte characters appear correctly (dollar, cents, Euro and something Chinese).
The second image shows the malformed JSON string rendered with UTF-8 encoding. In this image we see a marker in place of the malformed character, and the UTF8 multibyte characters appear correctly (dollar, cents, Euro and something Chinese).
 When it's shown in enlarged type and in a short character string it's relatively easy to spot the error, but finding a bad character in thousands of lines of JSON is a time consuming task. So I wrote a script to automate the process. The script output will look something like this, with clickable links to the byte positions of each of the malformed characters.
When it's shown in enlarged type and in a short character string it's relatively easy to spot the error, but finding a bad character in thousands of lines of JSON is a time consuming task. So I wrote a script to automate the process. The script output will look something like this, with clickable links to the byte positions of each of the malformed characters.
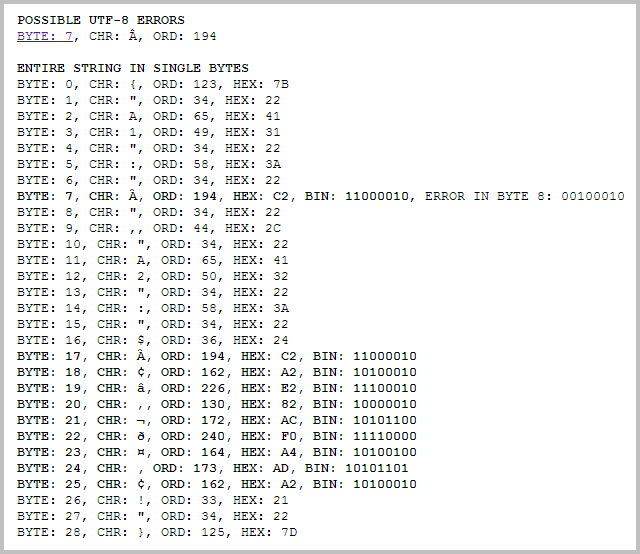 You should be able to put the URL of your JSON document (or for that matter, any UTF-8 document) on line 20 and run this script. If you're not looking at JSON, you would probably want to modify the script to remove the JSON tests.
You should be able to put the URL of your JSON document (or for that matter, any UTF-8 document) on line 20 and run this script. If you're not looking at JSON, you would probably want to modify the script to remove the JSON tests.
The script attempts to decode the JSON string (line 24) and will die with a happy message if it is successful. If the decode fails, the script will tell you the JSON error and continue processing. Beginning at line 55, the script will test each byte of the input string, looking for characters with byte values above 127. These are the characters that need to be tested for UTF-8 compliance. Each of these characters is given an anchor tag with an id= attribute equal to the character offset in the string. Lines 66-138 perform these tests, looking for appropriate multi-byte character formation. If any of these characters fail the UTF-8 test, the failing character offset is recorded in an array $sig (line 137).
Finally we check the $sig array and if it not empty we produce a set of links to the locations of the bytes that failed UTF-8 validation. With this sort of setup, it is easy to find the errant characters, even in very large UTF-8 documents. Feel free to copy this script and tailor it for your own use.
<?php // RAY_utf8_errors.php
error_reporting(E_ALL);
// SEE http://www.experts-exchange.com/Web_Development/Web_Languages-Standards/PHP/Q_28354239.html
// REF http://php.net/manual/en/function.utf8-encode.php
// REF http://php.net/manual/en/function.ord.php
// REF http://php.net/manual/en/function.decbin.php
// REF http://php.net/manual/en/function.json-last-error.php
// REF http://www.json.org/
// REF http://www.asciitable.com/
// REF http://en.wikipedia.org/wiki/UTF-8
// TRY THE SCRIPT BOTH WITH AND WITHOUT THIS STATEMENT
echo '<meta charset="utf8" />'; // GARBLES NON-UTF-8
// PREFORMAT FOR EASY VISUALIZATION
echo '<pre>';
// READ THE JSON TEST DATA
$url = 'path/to/json.txt';
$jso = file_get_contents($url);
// IF THE JSON IS VALID
$obj = json_decode($jso);
if ($obj) die("THE JSON AT $url IS VALID");
// IF THE JSON IS NOT VALID
switch (json_last_error())
{
case JSON_ERROR_NONE:
$err = 'No errors';
break;
case JSON_ERROR_DEPTH:
$err = 'Maximum stack depth exceeded';
break;
case JSON_ERROR_STATE_MISMATCH:
$err = 'Underflow or the modes mismatch';
break;
case JSON_ERROR_CTRL_CHAR:
$err = 'Unexpected control character found';
break;
case JSON_ERROR_SYNTAX:
$err = 'Syntax error, malformed JSON';
break;
case JSON_ERROR_UTF8:
$err = 'Malformed UTF-8 characters, possibly incorrectly encoded';
break;
default:
$err = 'Unknown error';
break;
}
echo $err . PHP_EOL;
// LOOK AT THE JSON STRING BYTE-BY-BYTE (NOT THE SAME AS CHARACTER-BY-CHARACTER)
$arr = str_split($jso);
$sig = array();
ob_start();
foreach ($arr as $ptr => $chr)
{
// GET THE NUMERIC VALUE OF THE BYTE
$ord = ord($chr);
$hex = strtoupper(dechex($ord));
$err = FALSE;
// FLAG THIS CHARACTER IF THE BYTE-CODE IS GT 127
if ($ord > 127)
{
$bin = decbin($ord);
echo PHP_EOL . '<a id="' . $ptr . '">' . "<b>BYTE: $ptr</a>, CHR: $chr, ORD: $ord, HEX: $hex, BIN: $bin</b>";
// GET POINTERS TO THE NEXT CHARACTERS
$pp1 = $ptr + 1;
$pp2 = $ptr + 2;
$pp3 = $ptr + 3;
// IF A FOUR-BYTE UTF-8 CHARACTER, NEXT 3 BYTES MUST START WITH '10'
$sub = substr($bin, 0, 5);
if ($sub == '11110')
{
$chs = array();
$chs[$pp1] = $arr[$pp1];
$chs[$pp2] = $arr[$pp2];
$chs[$pp3] = $arr[$pp3];
foreach ($chs as $ppp => $nxt)
{
$cod = decbin(ord($nxt));
$cod = str_pad($cod, 8, '0', STR_PAD_LEFT);
$utf = substr($cod,0,2);
if ($utf !== '10')
{
echo ", ERROR IN BYTE $ppp: $cod";
$err = TRUE;
}
}
}
// IF A THREE-BYTE UTF-8 CHARACTER, NEXT 2 BYTES MUST START WITH '10'
$sub = substr($bin, 0, 4);
if ($sub == '1110')
{
$chs = array();
$chs[$pp1] = $arr[$pp1];
$chs[$pp2] = $arr[$pp2];
foreach ($chs as $ppp => $nxt)
{
$cod = decbin(ord($nxt));
$cod = str_pad($cod, 8, '0', STR_PAD_LEFT);
$utf = substr($cod,0,2);
if ($utf !== '10')
{
echo ", ERROR IN BYTE $ppp: $cod";
$err = TRUE;
}
}
}
// IF A TWO BYTE UTF-8 CHARACTER, NEXT 1 BYTE MUST START WITH '10'
$sub = substr($bin, 0, 3);
if ($sub == '110')
{
$chs = array();
$chs[$pp1] = $arr[$pp1];
foreach ($chs as $ppp => $nxt)
{
$cod = decbin(ord($nxt));
$cod = str_pad($cod, 8, '0', STR_PAD_LEFT);
$utf = substr($cod,0,2);
if ($utf !== '10')
{
echo ", ERROR IN BYTE $ppp: $cod";
$err = TRUE;
}
}
}
// SAVE THE ERROR CHARACTER AND ITS APPROXIMATE LOCATION
if ($err) $sig[$ptr] = $chr;
}
// IF THE BYTE-CODE IS LE 127
else
{
echo PHP_EOL . "BYTE: $ptr, CHR: $chr, ORD: $ord, HEX: $hex";
}
}
$out = ob_get_clean();
// IF THERE WERE ANY CHARACTERS FLAGGED
if (!empty($sig))
{
echo PHP_EOL . '<b>POSSIBLE UTF-8 ERRORS IN $url</b>';
foreach ($sig as $ptr => $chr)
{
$ord = ord($chr);
echo PHP_EOL . '<a href="#' . $ptr . '">' . "BYTE: $ptr</a>, CHR: $chr, ORD: $ord";
}
echo PHP_EOL;
}
echo PHP_EOL . '<b>ENTIRE STRING IN SINGLE BYTES</b>';
echo $out;
Summary
This article has shown us some of the ways to move from the restrictive encoding of Extended ASCII (ISO-8859-1 and Windows-1252) to the more inclusive and increasingly popular UTF-8. As more and more of the world comes online, we must provide support for languages that require multibyte characters. UTF-8 encoding is, at present, the best way to achieve that.
References
https://www.compart.com/en/unicode
http://www.w3.org/MarkUp/html3/latin1.html
http://www.w3.org/wiki/Common_HTML_entities_used_for_typography
http://www.joelonsoftware.com/articles/Unicode.html
http://www.fileformat.info/info/unicode/utf8.htm
http://www.alanwood.net/demos/ansi.html
http://www.htmlhelp.com/reference/html40/entities/symbols.html
http://www.phptherightway.com/#php_and_utf8
http://www.itg.ias.edu/content/how-import-csv-file-uses-utf-8-character-encoding-0
http://en.wikipedia.org/wiki/Latin_alphabet
http://en.wikipedia.org/wiki/ASCII
http://en.wikipedia.org/wiki/ISO/IEC_646
http://en.wikipedia.org/wiki/ISO_8859-1
http://en.wikipedia.org/wiki/UTF-8
http://en.wikipedia.org/wiki/Unicode
http://en.wikipedia.org/wiki/Universal_Character_Set
http://en.wikipedia.org/wiki/List_of_typefaces#Unicode_fonts
http://php.net/manual/en/language.types.string.php
http://php.net/manual/en/language.types.string.php#language.types.string.details
http://php.net/manual/en/mbstring.supported-encodings.php
http://php.net/manual/en/ref.mbstring.php
http://php.net/manual/en/book.iconv.php
http://php.net/manual/en/mysqlinfo.concepts.charset.php
http://php.net/manual/en/function.mysql-set-charset.php
http://php.net/manual/en/mysqli.set-charset.php
http://php.net/manual/en/mysqli.character-set-name.php
http://php.net/manual/en/ref.pdo-mysql.connection.php
http://docs.oracle.com/cd/E17952_01/refman-5.5-en/charset-unicode.html
http://docs.oracle.com/cd/E17952_01/refman-5.5-en/charset-connection.html
http://dev.mysql.com/doc/refman/5.7/en/charset.html
http://dev.mysql.com/doc/refman/5.7/en/charset-unicode-utf8mb4.html
